Workflow¶
It's easier than ever to build an LLM prototype. When building LLM pipelines that are accurate, cheap and fast in production — engineers need to think like scientists. Superpipe makes this easy.
The Problem¶
Problem 1: You have no idea how your pipeline will perform on real data
To properly evaluate your extraction/classification pipelines, you need high-quality labeled data. It's not sufficient to evaluate on public benchmark data, you need to evaluate on your own data to reflect true accuracy.
Problem 2: You need to optimize your pipeline end-to-end across accuracy, cost and speed
You can get pretty far by optimizing your prompts, trying smaller models, or changing various parameters of your pipeline. However, optimizing each piece in isolation isn't enough. Pipelines need to be optimized end-to-end.
Problem 3: You need to monitor your pipeline in production and improve it over time
Once your pipeline is serving production traffic, you still need to know how it's doing. Data and models drift over time. As cheaper, faster and better models come out, you need to easily try them and swap them out when it makes sense.
The Solution¶
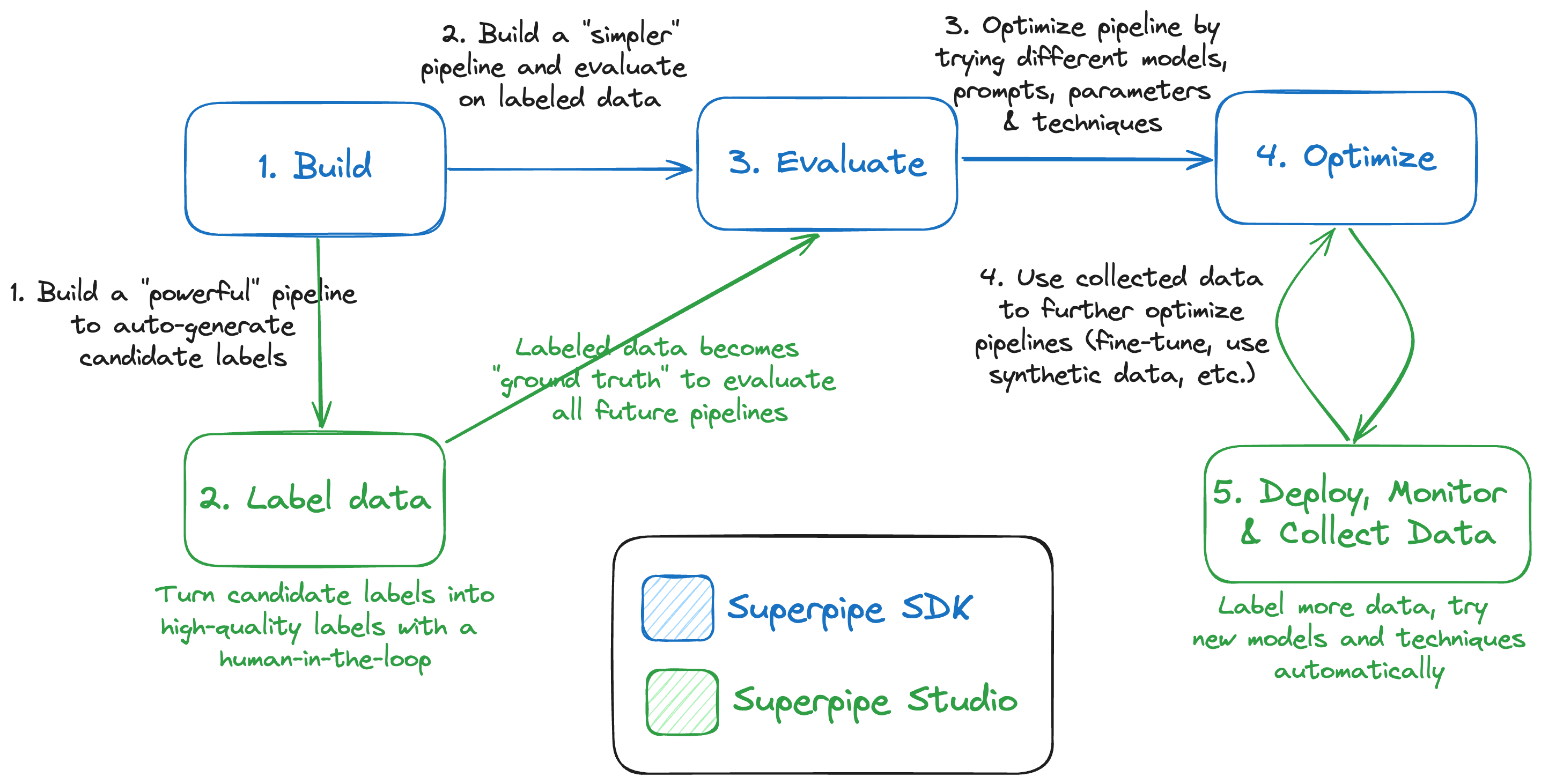
Superpipe helps you solve these problems by simplifying the following workflow:
Step 1: Build your pipeline
Superpipe makes it easy to build extraction and classification pipelines. You can also use langchain, LlamaIndex or your favorite LLM library. Superpipe acts as the glue between components and leaves you fully in control of the logic.
One of our principles is to abstract the boilerplate, not the logic. Using superpipe to build your pipeline, however, makes the following steps easier.
Step 2: Generate labeled data
Use your superpipe pipeline to create candidate labels. If you use a powerful model combined with powerful techniques you can generate reasonably accurate labels. Then you can manually inspect these labels with Superpipe Studio and fix the wrong ones. This is an important and often overlooked step. Without labeled data you can't evaluate your pipeline and without evaluation you're flying blind.
Step 3: Evaluate your pipeline
Armed with labeled data, you can build and evaluate cheaper and faster pipelines. You may want to combine open-source models with more complex techniques (like multi-step prompting, chain-of-though, etc.). You may want to iterate between Steps 1 & 3 by trying multiple approaches and comparing them on accuracy, cost and speed.
Step 4: Optimize your pipeline
A pipeline usually has many parameters - foundation models, prompts, structured outputs, k-values, etc. Superpipe lets you easily find the best combination of parameters by running a grid search over the parameter space. You can compare different approaches against each other and track your experiments with Studio.
Step 5: Deploy, monitor and further optimize
Once you've deployed the winning pipeline to production, Studio helps monitor the accuracy, cost and speed of the pipeline. It helps you run auto-evaluations on a sub-sample of production data to make sure model drift or data drift aren't hurting. It also lets you easily backtest the newest models and techniques and compare them to production.
The 5-step Superpipe workflow
While there are a number of general-purpose LLM libraries focused on different aspects of the above, Superpipe focuses on a specific problem (data extraction and classification) and the optimal workflow for the problem. It is designed with the following goals in mind:
Superpipe design goals
- Simplicity: easy to get started because there few abstractions to learn.
- Unopinionated: acts as connective tissue and abstracts boilerplate but leaves you in control of logic.
- Works with datasets: works natively with
pandasdataframes so you can evaluate and optimize over datasets. - Parametric: every aspect of the pipeline is exposed as a parameter, you can easily try different models or run hyperparameter searches.
- Plays well with others: use your favorite LLM library or tool, including langchain, LlamaIndex, DSpy, etc.